大話數(shù)據(jù)挖掘之聚類分析(下篇)
2021-02-02 15:59:00
次
人物介紹
許教授:國內(nèi)數(shù)據(jù)挖掘?qū)<?��、?85高校智能信息處理學術(shù)帶頭人
趙總:某電力公司總經(jīng)理
萬總:某超市集團營銷副總
李部長:某鋼鐵集團生產(chǎn)部部長
某985高校管理學院第五屆EMBA班的《數(shù)據(jù)挖掘及其應用》課程上��。
國內(nèi)數(shù)據(jù)挖掘專家����、智能信息處理學術(shù)帶頭人徐教授站在講臺上打開PPT說:“同學們����,大家好!今天我們接著上一節(jié)課關于聚類分析的內(nèi)容展開����。”
徐教授:“上節(jié)課我們講了k-Means算法和k-Medoids算法的第一個不足。第二個不足就是這兩種算法不適用于發(fā)現(xiàn)非球狀的簇��。原因是這類算法使用距離來描述數(shù)據(jù)之間的相似性��,但是���,對于非球狀數(shù)據(jù)集����,只用距離來描述是不夠的。”
“那遇到非球狀的聚類問題可怎么辦呢�?”萬總問道���。
徐教授答道:“對于這種情況��,要用密度來代替相似性設計聚類算法���,這就是基于密度的聚類算法即Density-based Method?���;诿芏鹊乃惴◤臄?shù)據(jù)對象的分布密度出發(fā)��,把密度足夠大的區(qū)域連接起來����,從而可以發(fā)現(xiàn)任意形狀的簇��,而且此類算法還能夠有效去除噪聲����。常見的基于密度的聚類算法有DBSCAN,OPTICS����,DENCLUE等。”
李部長已經(jīng)沉默了好長時間�����,他擔心萬總又有什么問題影響徐教授的教學進度���,趕緊插話道:“徐老師�,您剛才說還有一種層次方法����,這種聚類方法的思想……”
徐教授:“好,我現(xiàn)在就介紹一下層次方法即Hierarchical Method的基本思想�����。這種方法按數(shù)據(jù)分層建立簇��,形成一棵以簇為節(jié)點的樹。如果自底向上進行層次聚集����,則稱為凝聚的(Aggalomerative)層次聚類;如果自頂向下的進行層次分解�����,則稱為分裂法(Divisive)的層次聚類�。”
徐教授潤了潤嗓子,繼續(xù)講道:“凝聚的層次聚類首先將每個對象作為一個簇����,然后逐漸合并這些簇形成較大的簇�,直到所有的對象都在同一個簇中,或者滿足某個終止條件����。分裂的層次聚類與之相反,它首先將所有的對象置于一個簇中�,然后逐漸劃分為越來越小的簇,直到每個對象自成一簇����,或者達到了某個終止條件,例如達到了某個希望的簇數(shù)目,或兩個最近的簇之間的距離超過了一定的閾值�����。”
李部長一直認真地聽著��,不斷地點頭表示他明白了層次聚類的思想��。隨后�,他提問道:“徐老師,層次聚類算法有什么缺點����?”
徐教授:“層次方法可以在不同粒度水平上對數(shù)據(jù)進行探測,而且容易實現(xiàn)相似度量或距離度量��。但是����,單純的層次聚類算法的終止條件含糊,而且執(zhí)行合并或分裂簇的操作不可修正����,這很可能導致聚類結(jié)果質(zhì)量很低。另外�����,由于需要檢查和估算大量的對象或簇才能決定簇的合并或分裂,所以這種方法的可擴展性較差��。因此��,通常在解決實際聚類問題時要把層次方法與其他方法結(jié)合起來����。層次方法和其他聚類方法的有效結(jié)合可以形成多階段聚類,能夠改善聚類質(zhì)量��。這類方法包括BIRCH��、CURE�����、ROCK�、Chameleon算法等����。”
李部長迫不及待地說:“徐老師,您剛才講了這么多聚類方法����,我發(fā)現(xiàn)它們有一個共同的缺點���,就是算法無法回答數(shù)據(jù)對象到底可以聚集為多少類,據(jù)說你們研究團隊發(fā)明了一種視覺聚類算法�����,很好地解決了這一問題�����。我們幾個人昨天晚上還打賭��,我說您今天肯定會講視覺聚類算法�,可都要快下課了,您根本沒有提及視覺兩字����。我們都等不及了,您還是讓我們大家欣賞一下視覺聚類的神奇魅力吧���!”
說到視覺聚類算法����,徐教授臉上露出了會心的微笑。
“好的����。視覺聚類算法是基于我們所建立的尺度空間理論建立的,運用這種算法可以對衛(wèi)星傳回的原始圖像進行分析��,把具有相似屬性的事物聚到同一簇中��,例如將其用于香港地區(qū)地表高精度遙感圖像聚類�����、混雜遙感圖像中線狀目標如地震帶�、高速公路、機場跑道等目標識別等�����。”
李部長聽到這里����,激動得跳了起來:“徐老師���,看來視覺聚類算法有可能用于我們板材表面條紋�����、夾雜����、重皮等質(zhì)量問題的自動檢測,我們試試吧����!”
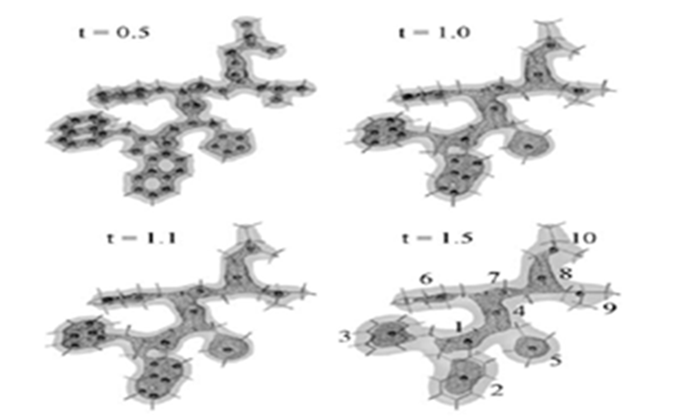
蛋白質(zhì)分析
趙總:“徐老師����,視覺聚類算法可太有用了,真棒���!”
徐教授非常高興:“不謙虛地說���,視覺聚類算法確實有其獨到之處,其基本思想非常獨特:將數(shù)據(jù)集看作圖像,將數(shù)據(jù)建模問題看作認知問題,通過模擬認知心理學的格式塔原理原理與生物視覺原理解決問題�。”
“且慢且慢,什么是格式塔原理�����?”李部長打斷了徐教授的話語��。
徐教授翻動了一下PPT:“很簡單�,格式塔原理就是物體的整體是由局部特征組織在一起的認知原則,請看屏幕����。”
“我們將相似率、連續(xù)率���、閉合率��、近鄰率和對稱率作為聚類的基本原則���,模擬人的眼睛由近到遠觀察景物的過程設計算法進行聚類。隨著人由近及遠��,也就是觀察尺度由小變大��,所看到的景物的層次會逐漸變化����,實際上這就是一個聚類的過程。”徐教授邊說邊翻了一下PPT�����。
李部長聽得如醉如癡�,看著PPT上視覺聚類的示意圖,突然���,他冒出了一個新的問題:“徐老師����,我明白了�����,在近處,所聚的類會很多��,在遠處���,所聚的類會很少�,在很遠處�����,所看到的東西就成為一個類別了����。您說,到底聚為多少類最為合適呢����?”
徐教授點了點頭:“李部長的雙核腦袋就是轉(zhuǎn)得快,一下子問道了視覺聚類的關鍵�����。隨著尺度σ由小變大,聚類的個數(shù)在發(fā)生變化�,但會出現(xiàn)尺度σ在很大范圍內(nèi)變化,而聚類的個數(shù)卻穩(wěn)定不變的情況��。這個聚類個數(shù)存活周期最長���,它就是最佳的聚類個數(shù)!”
“太妙了���,視覺聚類理論通過引進類的生存壽命概念����,給出了類的認知定義��,解決了聚類有效性問題��。數(shù)學上嚴格證明了結(jié)構(gòu)的因果性即類的演化單調(diào)性��,由此形成了尺度空間聚類的一般性理論框架�����。”李部長流利地對視覺聚類進行了總結(jié)�����。
徐教授對李部長的話感到納悶:“李部長,你不是做數(shù)據(jù)挖掘研究的�����,不可能給出這么深刻的總結(jié)吧��!”
李部長笑了笑:“嘿嘿���,這是我從網(wǎng)上看到的有人對視覺聚類方法的評價���。”
下課鈴響了,徐教授邊合上電腦邊說:“聚類方法我們就簡單學習到這兒�,下一節(jié)可咱們一起討論數(shù)據(jù)挖掘非常重要的內(nèi)容——預測。”
“今天關于關聯(lián)規(guī)則挖掘的內(nèi)容就介紹到這里�����。同學們��,下節(jié)課見�!”































據(jù)分析上手難?2招幫你快速生成高質(zhì)量數(shù)據(jù)可視化報表")



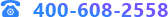

 Tempo商業(yè)智能平臺
Tempo商業(yè)智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數(shù)據(jù)工廠平臺
Tempo數(shù)據(jù)工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數(shù)據(jù)資產(chǎn)管理平臺
Tempo數(shù)據(jù)資產(chǎn)管理平臺 Tempo主數(shù)據(jù)管理平臺
Tempo主數(shù)據(jù)管理平臺


 陜公網(wǎng)安備 61019002000171號
陜公網(wǎng)安備 61019002000171號



