大模型的定義
大模型是指具有數(shù)千萬甚至數(shù)億參數(shù)的深度學習模型��。近年來�����,隨著計算機技術(shù)和大數(shù)據(jù)的快速發(fā)展�,深度學習在各個領(lǐng)域取得了顯著的成果,如自然語言處理�����,圖片生成��,工業(yè)數(shù)字化等��。為了提高模型的性能��,研究者們不斷嘗試增加模型的參數(shù)數(shù)量���,從而誕生了大模型這一概念。
大模型通常由深度神經(jīng)網(wǎng)絡(luò)構(gòu)建而成���,擁有數(shù)十億甚至數(shù)千億個參數(shù)�。大模型的設(shè)計目的是為了提高模型的表達能力和預測性能,能夠處理更加復雜的任務和數(shù)據(jù)�����。
大模型采用預訓練+微調(diào)的訓練模式�,在大規(guī)模數(shù)據(jù)上進行訓練后,能快速適應一系列下游任務的模型���。
大模型和小模型的區(qū)別
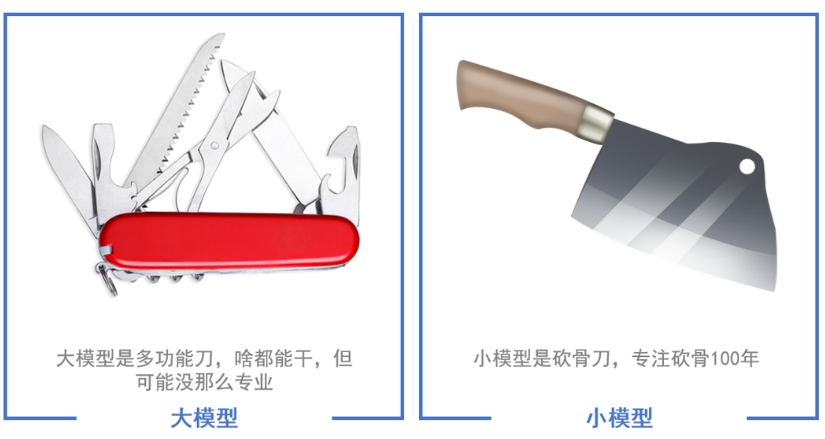
大模型和小模型在應用方面最大的區(qū)別是大模型偏向于全能化��、通用化�,而小模型一般偏向于解決某一垂直領(lǐng)域中的某個具體問題����。比如一個圖像識別小模型專門訓練用來識別車牌號,對車牌號可以有很好的識別精度����。但是一個圖像識別大模型不僅可以識別車牌號,還可以識別我們生活中碰到的大部分圖片�,而且站在我們?nèi)祟惖囊暯莵砜矗坪鯇D片中的內(nèi)容有自己的理解���,看起來擁有更高的智能化水平���。
另外相比小模型來說����,大模型通常具有更多的參數(shù)����,能夠?qū)W習更復雜的特征和模式。同時大模型的訓練數(shù)據(jù)集也會更大���,架構(gòu)更為復雜��,訓練起來也需要更高的計算資源�。
大模型的分類
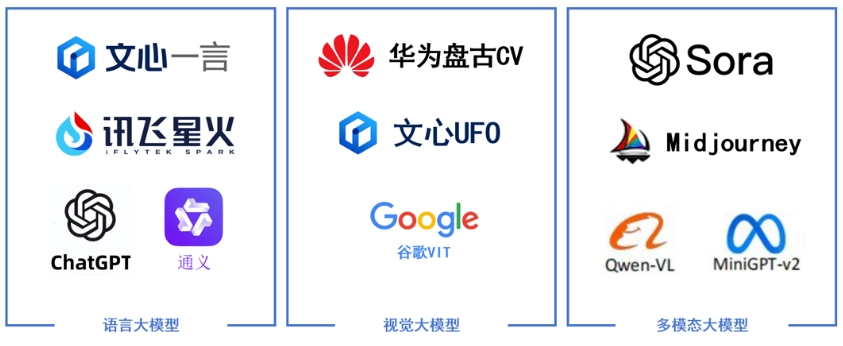
按照輸入數(shù)據(jù)類型的不同����,大模型主要可以分為以下三大類:
?語言大模型:是指在自然語言處理(NLP)領(lǐng)域中的一類大模型,通常用于處理文本數(shù)據(jù)和理解自然語言����。
?視覺大模型:是指在計算機視覺(CV)領(lǐng)域中使用的大模型��,通常用于圖像處理和分析。
?多模態(tài)大模型:是指能夠處理多種不同類型數(shù)據(jù)的大模型��,例如文本���、圖像���、音頻等多模態(tài)數(shù)據(jù)。
按照應用領(lǐng)域的不同���,大模型主要可以分為 L0���、L1、L2 三個層級:
?通用大模型 L0:是指可以在多個領(lǐng)域和任務上通用的大模型�����。通用大模型就像完成了大學前素質(zhì)教育階段的學生��,有基礎(chǔ)的認知能力��,數(shù)學����、英語�、化學�����、物理等各學科也都懂一點�����。
?行業(yè)大模型 L1:是指那些針對特定行業(yè)或領(lǐng)域的大模型�。它們通常使用行業(yè)相關(guān)的數(shù)據(jù)進行預訓練或微調(diào),以提高在該領(lǐng)域的性能和準確度�����。行業(yè)大模型就像選擇了某一個專業(yè)的大學生����,對自己專業(yè)下的相關(guān)知識有了更深入的了解。
?垂直大模型 L2:是指那些針對特定任務或場景的大模型��。它們通常使用任務相關(guān)的數(shù)據(jù)進行預訓練或微調(diào)�����,以提高在該任務上的性能和效果����。垂直大模型就像研究生,對特定行業(yè)下的某個具體領(lǐng)域有比較深入的研究�����。
大語言模型LLM
大語言模型(Large Language Model����,LLM)是大模型的子分類,是專門通過處理大量文本數(shù)據(jù)來理解和生成人類語言的AI系統(tǒng)��,從而執(zhí)行各種自然語言處理任務����,如文本分類、問答���、對話�����、內(nèi)容總結(jié)等�。我們最為常見的ChatGPT���、百度文心一言�、訊飛星火等都屬于大語言模型。
大語言模型LLM的基礎(chǔ)架構(gòu)
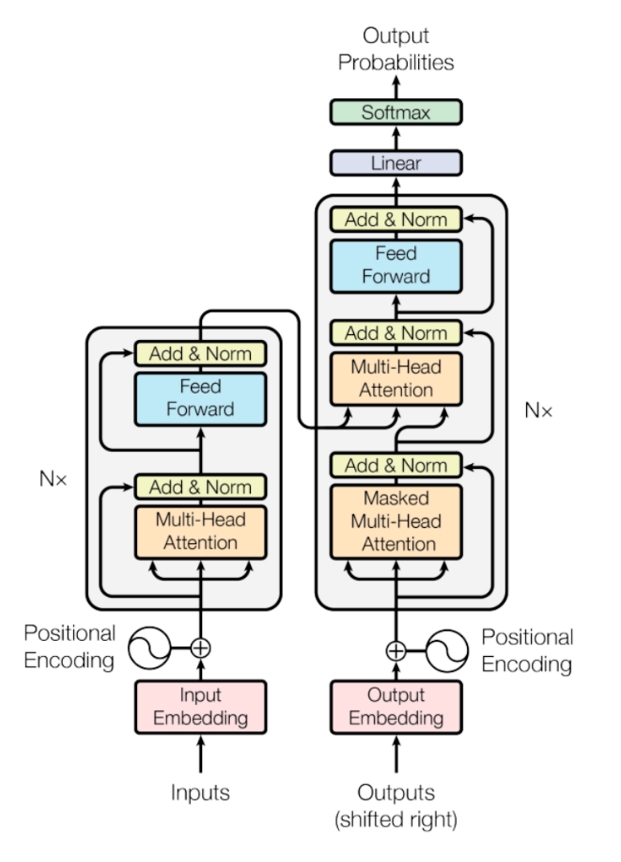
目前流行的大語言模型的架構(gòu)基本都沿用了當前NLP領(lǐng)域最熱門最有效的架構(gòu)—Transformer架構(gòu)��。Transformer架構(gòu)來源于谷歌在2017年發(fā)表的論文《Attention Is All You Need》���,翻譯過來就是注意力就是你需要的一切���。
注意力機制是大語言模型的核心機制,它讓模型在處理文本時����,能夠同時關(guān)注輸入中的所有詞匯,無論句子長短�����,都能精準捕捉到遠距離的語義關(guān)聯(lián)�����。例如���,在解析“華為公司發(fā)布了新款手機”這句話時���,模型能夠迅速聚焦“華為”與“手機”之間的關(guān)系�����,忽略“公司”或“發(fā)布”等詞的干擾,這種能力使得大語言模型在處理大段文本���、復雜語境時能夠真正理解其表達的核心含義��。
此外����,大語言模型通過位置編碼(Positional Encoding)的巧妙設(shè)計����,模型得以理解文本中的詞語位置和順序,準確把握語言的時序特性����,同時保留了高效的并行計算能力。
大語言模型LLM的應用場景
01��、知識庫問答系統(tǒng):
通過提問的方式��,快速查找企業(yè)知識庫中的內(nèi)容���,并通過大模型對內(nèi)容進行總結(jié)提煉并給出解決方案�����;如設(shè)備故障查詢����、設(shè)備運檢查詢���、員工智能助手等�。
02���、問答式BI系統(tǒng):
通過問答的方式讓大模型進行數(shù)據(jù)庫查詢���,并返回數(shù)據(jù)結(jié)果、可視化圖形等內(nèi)容���,供用戶進行便捷的數(shù)據(jù)分析����。
03、智能體系統(tǒng):
將大模型的自然語言能力和小模型的垂直領(lǐng)域能力進行整合�,形成企業(yè)智能體系統(tǒng),滿足設(shè)備故障預測�����、電力負荷預測�、供應商評估分析等智能化應用和預測場景��。
大模型的發(fā)展是當前人工智能時代科技進步的必然趨勢���,甚至可以媲美工業(yè)革命般的歷史意義���。大模型這種新技術(shù)也幫我們帶來了更多生活、工作的有利工具�,同時為企業(yè)帶來了從數(shù)字化邁向智能化的可能。因此�,在這個數(shù)字化發(fā)展日新月異的時代,我們只有主動擁抱這種變化���,緊跟數(shù)字化�、智能化潮流,才能確保我們在激烈的競爭中立于不敗之地����。






























:大模型知識的進化之路")
數(shù)智化轉(zhuǎn)型中可以做哪些事情?")




 Tempo商業(yè)智能平臺
Tempo商業(yè)智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數(shù)據(jù)工廠平臺
Tempo數(shù)據(jù)工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數(shù)據(jù)治理平臺
Tempo數(shù)據(jù)治理平臺 Tempo主數(shù)據(jù)管理平臺
Tempo主數(shù)據(jù)管理平臺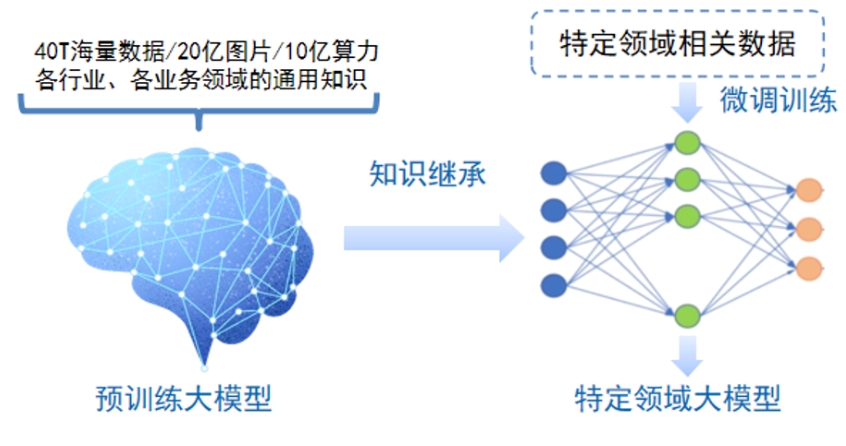



 陜公網(wǎng)安備 61019002000171號
陜公網(wǎng)安備 61019002000171號



