分類分析和回歸分析是機(jī)器學(xué)習(xí)中兩個(gè)非常重要的概念�,在實(shí)際應(yīng)用中,它們各自有著不同的應(yīng)用場景��?��;貧w分析適合于需要預(yù)測連續(xù)數(shù)值型數(shù)據(jù)的情況�����,而分類分析則針對離散類型的問題���,比如二分類、多分類等����。回歸分析和分類分析的本質(zhì)是一樣的����,都是有監(jiān)督學(xué)習(xí),但是兩者在輸出數(shù)據(jù)類型���、得到的算法結(jié)果以及模型評(píng)估指標(biāo)等方面存在一些差異��。
(1)輸出數(shù)據(jù)的類型�����?�;貧w輸出的是連續(xù)數(shù)據(jù)類型����,比如我們通過學(xué)習(xí)時(shí)間預(yù)測學(xué)生的考試分?jǐn)?shù),這里的預(yù)測結(jié)果分?jǐn)?shù)�,是連續(xù)數(shù)據(jù)。分類輸出的是離散型數(shù)據(jù)��,也就是分類的標(biāo)簽���,比如我們通過學(xué)生學(xué)習(xí)預(yù)測考試是否通過�����,這里的預(yù)測結(jié)果是考試通過或者不通過����,這兩種離散數(shù)據(jù)。
(2)我們想要通過機(jī)器學(xué)習(xí)算法得到什么���。分類得到是一個(gè)決策面�����,用于對數(shù)據(jù)集中的數(shù)據(jù)進(jìn)行分類?;貧w得到是一個(gè)最優(yōu)擬合線,這個(gè)線條可以最好的接近數(shù)據(jù)集中的各個(gè)點(diǎn)����。
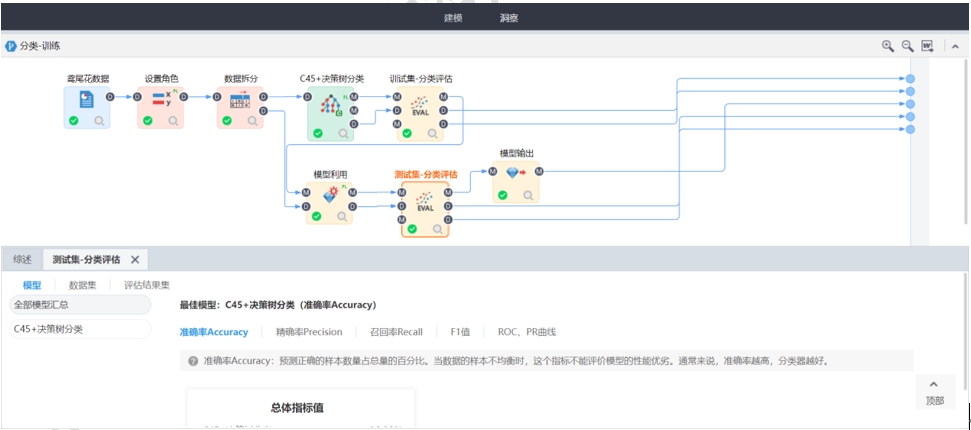
(3)模型評(píng)估指標(biāo)不同。分類中我們通常會(huì)使用準(zhǔn)確率作為指標(biāo)�。回歸中我們通常用決定系數(shù)R2來評(píng)估模型的好壞��。
分類分析和回歸分析步驟相同�����,在這里不做過多贅述。區(qū)別在于分類算法必須設(shè)置自變量����,自變量可以是連續(xù)型(數(shù)值)也可以是離散型(字符),也必須設(shè)置因變量�,且因變量必須是一個(gè)離散型(字符)。
平臺(tái)內(nèi)置分類算法:邏輯回歸分類���、樸素貝葉斯��、Xgboost分類�����、貝葉斯網(wǎng)絡(luò)分類�����、BP神經(jīng)網(wǎng)絡(luò)分類�、隨機(jī)森林分類�����、支持向量機(jī)分類���、 CART��、ID3分類�、C45+決策樹分類、梯度提升決策樹分類���、L1/2稀疏迭代分類�、RBF神經(jīng)網(wǎng)絡(luò)分類���、KNN�、線性判別分類和Adaboost分類���。當(dāng)然也可選擇自動(dòng)分類節(jié)點(diǎn)構(gòu)建模型。
分類的模型評(píng)估指標(biāo)包括準(zhǔn)確率�����、精確率����、召回率、F1值�����、ROC曲線�、PR曲線��、Lift曲線��、Gains曲線�����、Fini系數(shù)��、K-S曲線等��,具體的指標(biāo)說明和曲線圖可以在平臺(tái)洞察中查看�����。
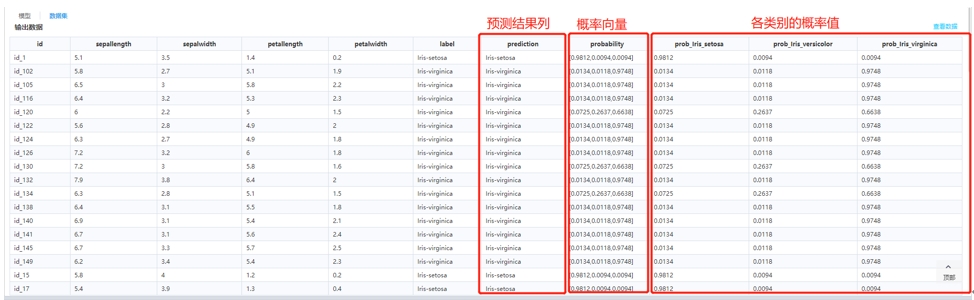
再來看數(shù)據(jù)集的情況����,可以看到屬性“prediction”為分類預(yù)測結(jié)果�,“probability”為每個(gè)類別的概率值。
同樣��,我們也可以利用訓(xùn)練好的模型進(jìn)行類別預(yù)測��,如下圖:
總之,分類分析是機(jī)器學(xué)習(xí)中非常重要的分析方法之一�����,它的應(yīng)用廣泛��,可用于各種分類問題����。在實(shí)踐過程中,我們需要根據(jù)具體的任務(wù)需求選擇合適的分類算法��,并綜合考慮不同的模型評(píng)估指標(biāo)�����,以達(dá)到更為準(zhǔn)確和有效的分類結(jié)果���。分類分析將會(huì)在未來的人工智能領(lǐng)域發(fā)揮越來越重要的作用,我們期待著這項(xiàng)技術(shù)的日益發(fā)展��。






























:大模型知識(shí)的進(jìn)化之路")





 Tempo商業(yè)智能平臺(tái)
Tempo商業(yè)智能平臺(tái) Tempo人工智能平臺(tái)
Tempo人工智能平臺(tái) Tempo數(shù)據(jù)工廠平臺(tái)
Tempo數(shù)據(jù)工廠平臺(tái) Tempo指標(biāo)平臺(tái)
Tempo指標(biāo)平臺(tái) Tempo數(shù)據(jù)治理平臺(tái)
Tempo數(shù)據(jù)治理平臺(tái) Tempo主數(shù)據(jù)管理平臺(tái)
Tempo主數(shù)據(jù)管理平臺(tái)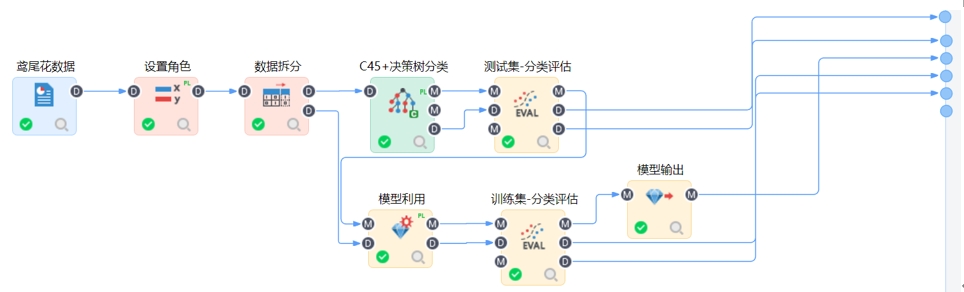



 陜公網(wǎng)安備 61019002000171號(hào)
陜公網(wǎng)安備 61019002000171號(hào)



