在大數(shù)據(jù)分析數(shù)據(jù)處理過程中�,關(guān)鍵特征該如何篩選?
2023-04-11 18:39:42
次
1.為什么要做關(guān)鍵特征篩選?
在數(shù)據(jù)量與日俱增的時代,我們收集到的數(shù)據(jù)越來越多�����,能運用到數(shù)據(jù)分析挖掘的數(shù)據(jù)也逐漸豐富起來��,但同時�,我們也面臨著如何從龐大的數(shù)據(jù)中篩選出與我們業(yè)務(wù)息息相關(guān)的數(shù)據(jù)。(大背景)從數(shù)據(jù)中挖掘潛在的規(guī)律�,輔助我們在實際業(yè)務(wù)中進行決策。
在現(xiàn)實任務(wù)中經(jīng)常會遇到維數(shù)災(zāi)難問題��,屬性過多造成的�。可以降低學(xué)習(xí)任務(wù)的難度�����,不相關(guān)的特征就是噪聲����。它有助于減少數(shù)據(jù)集的大小和復(fù)雜性,反過來使我們可以用更少的時間來訓(xùn)練模型�,更少的計算成本來訓(xùn)練機器學(xué)習(xí)模型和進行推理;具有較少特征的簡單機器學(xué)習(xí)模型更容易理解和解釋��;它可以避免過擬合。因為特征越多�����,模型就越復(fù)雜���,這就帶來了維數(shù)的麻煩 (錯誤會隨著特征數(shù)量的增加而增加) ����。
特征選擇目的:1)減少特征數(shù)量����、降維,使模型泛化能力更強�����,加速模型訓(xùn)練����,減少過擬合;2)增強對特征和特征值之間的理解����。
2.做關(guān)鍵特征篩選的常見問題有哪些?
問題在于���,1)在面對未知領(lǐng)域的時候�,很難有足夠的知識去判斷特征與我們的目標是不是相關(guān)��,特征與特征之間是不是相關(guān)����。這時候,就需要一些數(shù)學(xué)和工程上的辦法來幫助我們盡可能地把恰好需要的特征選擇出來����。2)特征與特征之間往往不是獨立的,因此特征選擇往往把要選擇的特征當作一個子集進行搜索(單獨特征最優(yōu)組合)。3)樣本與樣本之間往往存在特征分布的重疊�����。(基于類內(nèi)類間的特征選擇方法不能反映樣本分布重疊的情況)�����。
3.做數(shù)據(jù)篩選的3類方法
選擇哪種特征選擇方法���?為自己打造一個投票選擇器
實現(xiàn)我們討論過的幾種特征選擇方法��。您的選擇可能取決于時間��、計算資源和數(shù)據(jù)度量級別等因素�����。只要運行盡可能多的不同方法就可以了��。然后�,對于每個特征,記下建議將此特征保留在數(shù)據(jù)集中的選擇方法的百分比�。如果超過50%的方法投票贊成保留,則保留它該特征�����,否則�����,請丟棄它��。
這種方法背后的思想是���,雖然一些方法可能由于其內(nèi)在的偏見而對某些特征做出錯誤的判斷����,但多種方法的集合應(yīng)該可以正確地獲得有用的特征集�。
1)統(tǒng)計方法
?定義:其最大優(yōu)勢是不依賴于模型,僅從特征的角度來挖掘其價值高低�����,從而實現(xiàn)特征排序及選擇�。由于它們與模型無關(guān),因此它們也更通用��;它們不會對任何特定的算法進行過度匹配���。它們也很容易解釋:如果一個特征與目標沒有統(tǒng)計關(guān)系��,它就會被丟棄���。其核心在于對特征進行排序——按照特征價值高低排序后,即可實現(xiàn)任意比例/數(shù)量的特征選擇或剔除���。
缺點是��,他們分別單獨查看每個特征�,評估其與目標的關(guān)系。這使得他們很容易放棄一些有用的特征��,而這些特征本身是目標的弱預(yù)測因子��,但與其他特征結(jié)合后會為模型增加很多價值��。
?包含:方差選擇�、方差分析、相關(guān)系數(shù)
?適用場景:/
?優(yōu)勢/各種方法之間的對比或差異:
方差選擇�����,計算各個特征的方差���,然后根據(jù)閾值����,選擇方差大于閾值的特征����。優(yōu)點:計算量較小,只需計算所有特征的方差即可��;可作為第一次特征選擇對特征進行過濾,降低后續(xù)算法的計算成本���。缺點:比較依賴閾值的選取�,如果閾值選取過高����,會篩選掉許多有用特征��;閾值過低�,又會留下較多無用數(shù)據(jù);一些作用較大的數(shù)據(jù)可能因為數(shù)據(jù)不平衡等問題出現(xiàn)方差較小的情況����,而這些特征容易被方差過濾法給誤刪了;只能用于離散型數(shù)據(jù)���,對于連續(xù)型數(shù)據(jù)���,應(yīng)先劃分區(qū)間,將連續(xù)性化成離散型���,再進行方差過濾�����。
?適用場景:由于方差過濾法的缺點較大���,所以往往是先采用方差過濾法將一些變化極小或為無變化的特征先行篩選掉�����,減少一部分數(shù)據(jù)���,然后再采用模型方法進行二次篩選。
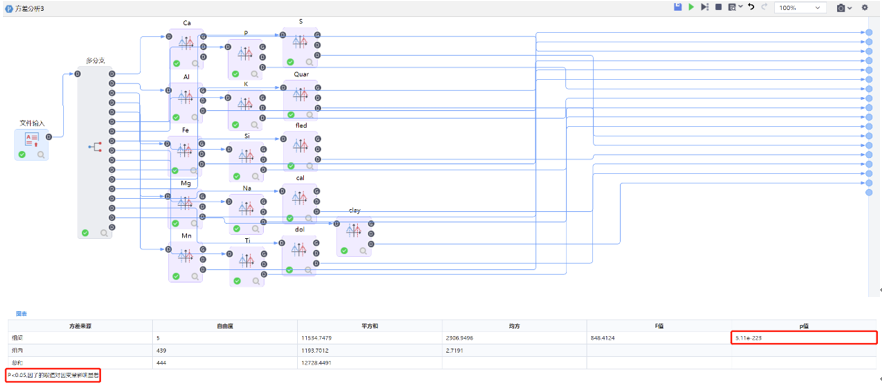
方差分析����,是一種假設(shè)檢驗的方法,它是分析目標在于檢驗各組的均值間差異是否在統(tǒng)計意義上顯著���。優(yōu)點:(1)它不受統(tǒng)計組數(shù)的限制���,可接受大樣本統(tǒng)計數(shù)量進行多重比較,能夠充分地利用試驗所提供數(shù)據(jù)來估計試驗誤差��,可以將各因素對試驗指標的影響從試驗誤差中分離開�,是一種定量分析方法,可比性強,分析精度高��;(2)方差分析可以考察多個因素的交互作用����。缺點:(1)涉及到全部數(shù)據(jù),計算復(fù)雜����;(2)前提條件較為苛刻,需要數(shù)據(jù)樣本之間相互獨立�,且滿足正態(tài)分布和方差齊性�,所以需要對數(shù)據(jù)進行方差齊性檢驗。
相關(guān)系數(shù):其主要思想是通過計算各個特征之間的相關(guān)系數(shù)��,篩選出與目標變量相關(guān)性最高的特征��。優(yōu)點是��,最簡單的�,能幫助理解特征和響應(yīng)變量之間關(guān)系的方法,該方法衡量的是變量之間的線性相關(guān)性�。速度快、易于計算��,經(jīng)常在拿到數(shù)據(jù)(經(jīng)過清洗和特征提取之后的)之后第一時間就執(zhí)行。缺陷是����,它假設(shè)兩個變量都是正態(tài)分布的,并且只測量它們之間的線性相關(guān)性�。當相關(guān)性為非線性時,皮爾遜r將無法檢測到它�����,即使它真的很強��。
效果:簡單描述操作+最終效果圖
方差選擇
輸出大于閾值的字段名為重要特征����。
方差分析
相關(guān)系數(shù)
2)模型方法
?定義: 它使用一個模型對不同的特征子集進行評分,最終選擇最佳的特征����。每個新子集用于訓(xùn)練一個模型,該模型的性能隨后在保持集上進行評估���。選擇產(chǎn)生最佳模型性能的特征子集����。
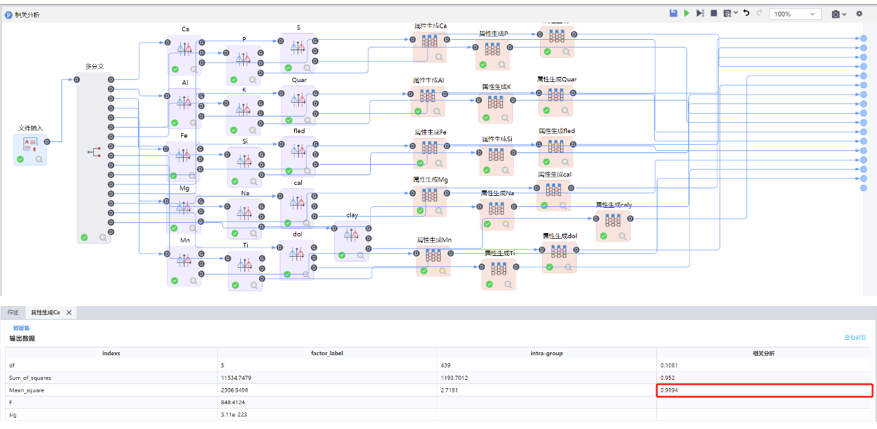
?包含:邏輯回歸分類、隨機森林分類���、梯度提升決策樹分類�、ReliefF���、RFE
?適用場景:如果我們并不了解業(yè)務(wù)��,或者有成千上萬的特征�����,那我們也可以使用算法來幫助我們����?����;蛘?,可以讓算法先幫助我們篩選過一遍特征�,然后在少量的特征中,我們再根據(jù)業(yè)務(wù)常識來選擇更少量的特征�����。
?優(yōu)勢/各種方法之間的對比或差異:
邏輯回歸分類、隨機森林��、RFE等���,可以幫助我們識別哪些變量對于分類預(yù)測最有用�����。這可以提高模型的準確性����。將特征選擇看做是一個黑盒問題:即僅需指定目標函數(shù)(這個目標函數(shù)一般就是特定模型下的評估指標)�,通過一定方法實現(xiàn)這個目標函數(shù)最大化,而不關(guān)心其內(nèi)部實現(xiàn)的問題�。進一步地,從具體實現(xiàn)的角度來看���,給定一個含有N個特征的特征選擇問題�,可將其抽象為從中選擇最優(yōu)的K個特征子集從而實現(xiàn)目標函數(shù)取值最優(yōu)�。
優(yōu)點是,為特定類型的模型提供性能最佳的特征集��。缺點是,可能會過度適用于模型類型����,如果希望使用不同的機器學(xué)習(xí)模型嘗試它們,則它們生成的特征子集可能不會泛化�。計算量大。他們需要訓(xùn)練大量的模型���,這可能需要一些時間和計算能力���。
?效果:簡單描述操作+最終效果圖
邏輯回歸
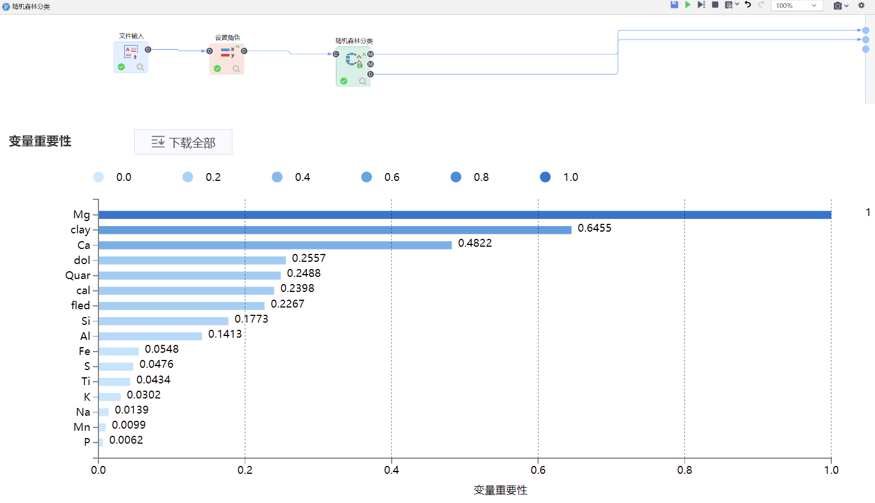
隨機森林
梯度提升決策樹
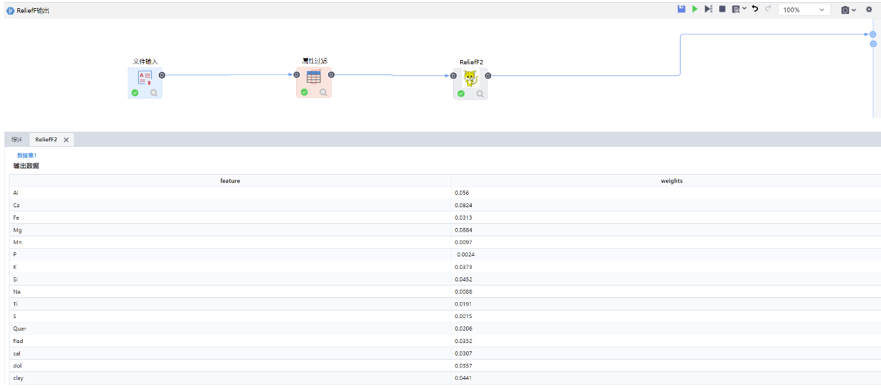
ReliefF
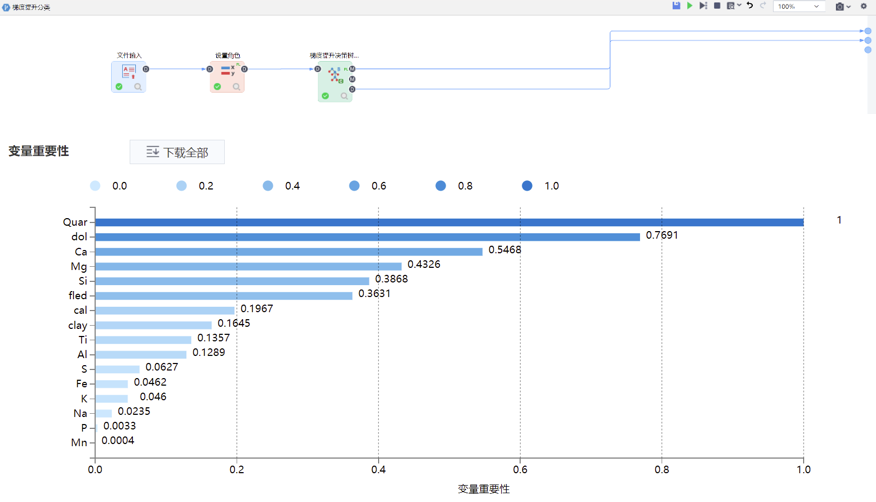
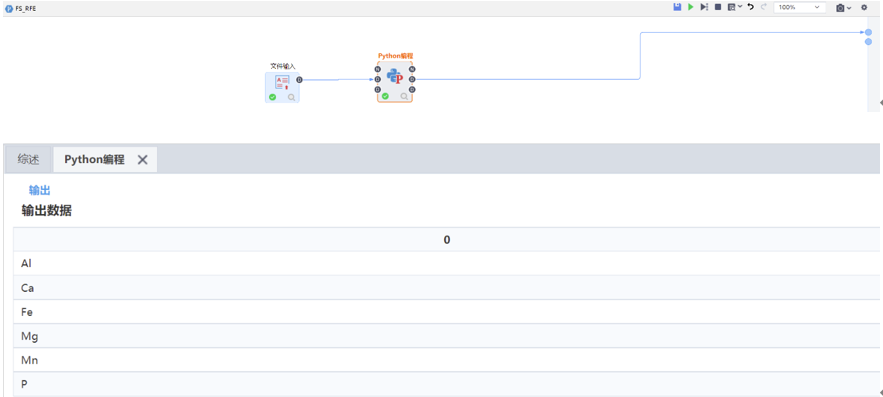
RFE
僅展示重要特征。
3)集成方法
?定義:python分析重要性的幾個工具�����。
?包含:Shap�����、Permutation Importance�、Boruta��、Partial Dependence Plots
?適用場景:/
?優(yōu)勢/各種方法之間的對比或差異:
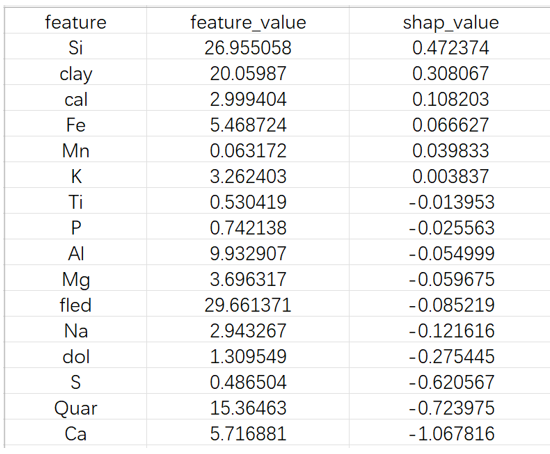
Shap做特征篩選�,能夠提高性能�����,但缺點是時間成本高�����。參數(shù)組合越多���,或者選擇過程越準確,持續(xù)時間越長���。這是我們實際上無法克服的物理限制����。
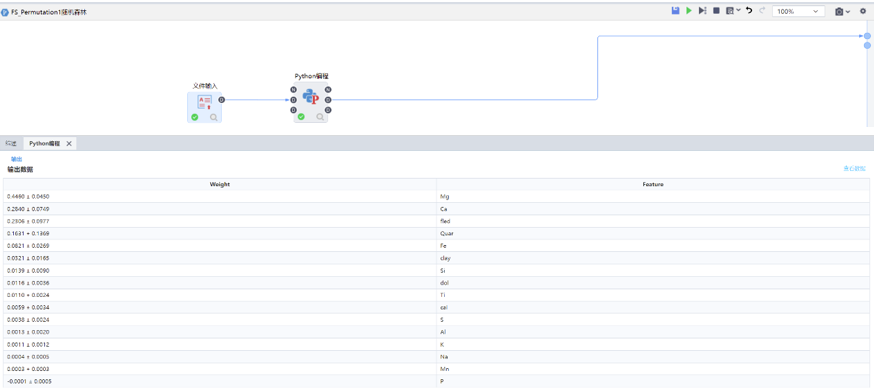
Permutation Importance適用于表格型數(shù)據(jù)���,其對于特征重要性的評判取決于該特征被隨機重排后��,模型表現(xiàn)評分的下降程度����。優(yōu)點是����,計算速度快���;應(yīng)用廣泛、易于理解����;與我們期望一個特征重要性度量所具有的性質(zhì)一致。
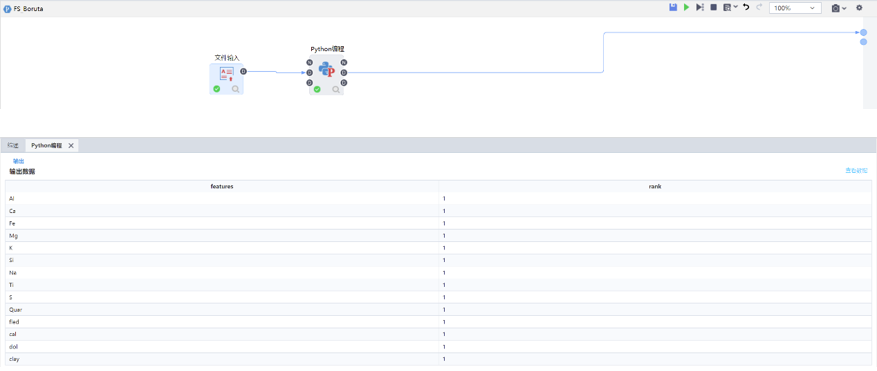
Boruta是一種簡單但統(tǒng)計上很優(yōu)雅的算法���。它使用來自隨機森林模型的特征重要性度量來選擇特征的最佳子集��,并通過引入兩個極好的思路來實現(xiàn)����。Boruta對特征進行了精確的分類��,而不是排序���,這與許多其他特征選擇方法形成了鮮明對比�����。
Partial Dependence Plots跟排列重要性一樣�,部分依賴圖也是要在擬合出模型之后才能進行計算��。
?效果:簡單描述操作+最終效果圖
Permutation Importance
Boruta
Shap
Partial Dependence Plots
波動大說明特征越重要����。






























:大模型知識的進化之路")




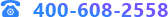

 Tempo商業(yè)智能平臺
Tempo商業(yè)智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數(shù)據(jù)工廠平臺
Tempo數(shù)據(jù)工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數(shù)據(jù)治理平臺
Tempo數(shù)據(jù)治理平臺 Tempo主數(shù)據(jù)管理平臺
Tempo主數(shù)據(jù)管理平臺



 陜公網(wǎng)安備 61019002000171號
陜公網(wǎng)安備 61019002000171號



