時(shí)間序列數(shù)據(jù)挖掘:利用機(jī)器學(xué)習(xí)揭示趨勢(shì)和模式
2023-12-14 16:17:00
次
隨著數(shù)據(jù)技術(shù)的不斷發(fā)展和普及,數(shù)據(jù)分析和數(shù)據(jù)挖掘成為了企業(yè)和組織在日常運(yùn)營(yíng)和戰(zhàn)略決策中不可或缺的工具�。而時(shí)間序列分析,作為一種重要的數(shù)據(jù)分析和數(shù)據(jù)挖掘方法���,已經(jīng)被廣泛應(yīng)用于各個(gè)領(lǐng)域�����,如金融���、經(jīng)濟(jì)����、市場(chǎng)營(yíng)銷(xiāo)等��。通過(guò)對(duì)時(shí)間序列數(shù)據(jù)的分析����,可以發(fā)現(xiàn)潛在的規(guī)律和趨勢(shì),幫助決策者更準(zhǔn)確地預(yù)測(cè)未來(lái)市場(chǎng)走向����、評(píng)估風(fēng)險(xiǎn)和機(jī)會(huì),制定更加優(yōu)化的戰(zhàn)略或運(yùn)營(yíng)計(jì)劃�����。本文將介紹時(shí)間序列分析的基本概念和方法��,以及如何利用數(shù)據(jù)分析�����、數(shù)據(jù)挖掘等技術(shù)對(duì)這種方法進(jìn)行優(yōu)化和改進(jìn)�����。
第一步接入數(shù)據(jù):
時(shí)間序列算法要求接入結(jié)構(gòu)化數(shù)據(jù)���,自變量數(shù)據(jù)類(lèi)型為數(shù)值型�����,不支持字符型�����、日期型和文本型等��。若接入的自變量數(shù)據(jù)不滿足時(shí)間序列分析的數(shù)據(jù)要求��,可以通過(guò)屬性變化節(jié)點(diǎn)進(jìn)行數(shù)據(jù)類(lèi)型轉(zhuǎn)換或重新接入數(shù)據(jù)��。
第二步設(shè)置角色:
通過(guò)設(shè)置角色節(jié)點(diǎn)確定時(shí)間序列分析研究的屬性列����,設(shè)置為自變量���。時(shí)間序列算法必須設(shè)置自變量���,不支持設(shè)置因變量���,自變量?jī)H支持連續(xù)型(數(shù)值)屬性,并且只能有一個(gè)自變量����。
一般建議在設(shè)置角色之前先進(jìn)行數(shù)據(jù)的可視化探索,利用平臺(tái)提供的圖表分析節(jié)點(diǎn)�����,如散點(diǎn)圖等識(shí)別序列是否是非隨機(jī)序列,如果是非隨機(jī)序列,則觀察其平穩(wěn)性��。對(duì)非平穩(wěn)的時(shí)間序列數(shù)據(jù)采用差分進(jìn)行平穩(wěn)化處理,直到處理后序列是平穩(wěn)的非隨機(jī)序列����。因?yàn)閷?duì)于時(shí)間序列數(shù)據(jù),最重要的檢驗(yàn)就是時(shí)間序列數(shù)據(jù)是否為白噪聲數(shù)據(jù)、時(shí)間序列數(shù)據(jù)是否平穩(wěn),以及對(duì)時(shí)間序列數(shù)據(jù)的自相關(guān)系數(shù)和偏自相關(guān)系數(shù)進(jìn)行分析��。如果時(shí)間序列數(shù)據(jù)是白噪聲數(shù)據(jù), 說(shuō)明其沒(méi)有任何有用的信息����。針對(duì)時(shí)間序列數(shù)據(jù)的很多分析方法,都要求所研究的時(shí)間序列數(shù)據(jù)是平穩(wěn)的,所以判斷時(shí)間序列數(shù)據(jù)是否平穩(wěn),以及如何將非平穩(wěn)的時(shí)間序列數(shù)據(jù)轉(zhuǎn)化為平穩(wěn)序列數(shù)據(jù),對(duì)時(shí)間序列數(shù)據(jù)的建模研究是非常重要的,如果模型沒(méi)有通過(guò)檢驗(yàn)(檢驗(yàn)?zāi)P蜌埐钚蛄惺欠駷榘自肼曅蛄校?�,需要?duì)其進(jìn)行重新識(shí)別。
第三步建立數(shù)據(jù)分析模型:
根據(jù)業(yè)務(wù)分析方案和所識(shí)別出來(lái)的特征建立相應(yīng)的時(shí)間序列模型�����。平臺(tái)內(nèi)置9種時(shí)間序列算法可以直接拖拽使用��,并配置對(duì)應(yīng)的模型參數(shù)���,包括:ARIMA、稀疏時(shí)間序列��、指數(shù)平滑�、移動(dòng)平均、向量自回歸��、X11��、X12���、回聲狀態(tài)網(wǎng)絡(luò)和灰色預(yù)測(cè)�����。當(dāng)我們不清楚當(dāng)前數(shù)據(jù)更適合哪種時(shí)間序列算法��,或不清楚多個(gè)模型中哪個(gè)模型效果更好時(shí)�,我們有兩種處理方案:方案一,通過(guò)多分支節(jié)點(diǎn)將自變量相同的輸入數(shù)據(jù)同時(shí)傳遞給多個(gè)不同的時(shí)間序列模型��,由平臺(tái)推薦出多個(gè)模型中的最優(yōu)模型�����;第二種���,通過(guò)自動(dòng)時(shí)序節(jié)點(diǎn)選擇多個(gè)時(shí)間序列算法一次性構(gòu)建模型�����,該節(jié)點(diǎn)內(nèi)嵌自動(dòng)擇參功能��,將多個(gè)算法及其對(duì)應(yīng)的多組參數(shù)生成的多個(gè)模型進(jìn)行評(píng)估比較�,最終幫助我們推薦出最佳算法及相應(yīng)的最佳參數(shù)組合���。
第四步數(shù)據(jù)分析模型評(píng)估:
利用時(shí)間序列評(píng)估節(jié)點(diǎn)檢驗(yàn)時(shí)序模型的可靠性���,在洞察中根據(jù)一些評(píng)價(jià)的指標(biāo)(如相對(duì)誤差等指標(biāo))或者圖表展示,獲得質(zhì)量最佳的時(shí)序模型��。
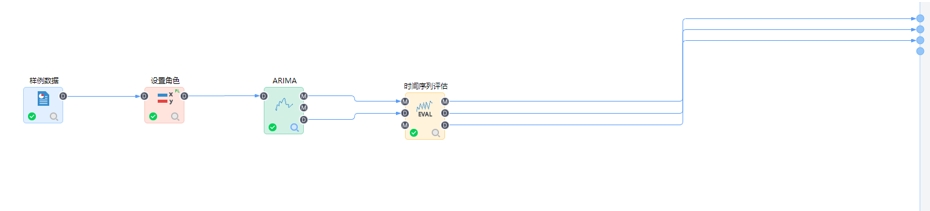
完成上述建模之后執(zhí)行流程,流程執(zhí)行成功后自動(dòng)跳轉(zhuǎn)至洞察頁(yè)面��,在洞察頁(yè)面點(diǎn)擊可以查看模型的分析結(jié)果���,我們通過(guò)示例流程來(lái)詳細(xì)介紹��。點(diǎn)擊【ARIMA】查看模型結(jié)果����,包含預(yù)測(cè)值真實(shí)值對(duì)比曲線圖����、自相關(guān)圖����、偏相關(guān)圖及統(tǒng)計(jì)檢驗(yàn)量。

點(diǎn)擊【時(shí)間序列模型評(píng)估】查看模型對(duì)歷史數(shù)據(jù)預(yù)測(cè)的評(píng)估如下:
從誤差來(lái)看�����,模型的平均相對(duì)誤差為19%�,所以模型結(jié)果比較一般。再來(lái)看數(shù)據(jù)集的情況�����,可以看到新增的prediction預(yù)測(cè)結(jié)果列�。
第五步利用算法模型預(yù)測(cè):
需要注意的是,平臺(tái)中時(shí)間序列的模型不支持連接模型利用節(jié)點(diǎn)���,對(duì)于新數(shù)據(jù)只能重新進(jìn)行預(yù)測(cè)��。那么在上述示例中模型構(gòu)建完成后�����,就可以利用模型對(duì)系統(tǒng)容量進(jìn)行預(yù)測(cè)�,其模型應(yīng)用過(guò)程如下:
1、從系統(tǒng)中每日定時(shí)抽取服務(wù)器磁盤(pán)數(shù)據(jù)�;
2、對(duì)定時(shí)抽取的數(shù)據(jù)進(jìn)行清洗�、數(shù)據(jù)變換預(yù)處理等操作;
3���、將預(yù)處理后的數(shù)據(jù)存放到數(shù)據(jù)庫(kù)中����,定時(shí)的調(diào)用流程對(duì)服務(wù)器磁盤(pán)進(jìn)行預(yù)測(cè)�,預(yù)測(cè)后四天的磁盤(pán)使用大?。?/span>
4��、將預(yù)測(cè)值與磁盤(pán)的總?cè)萘勘容^����,獲得預(yù)測(cè)的磁盤(pán)使用率。如果某一天預(yù)測(cè)的使用率達(dá)到業(yè)務(wù)設(shè)置的預(yù)警級(jí)別�����,就會(huì)以預(yù)警的方式提醒系統(tǒng)管理員。






























:大模型知識(shí)的進(jìn)化之路")




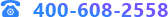

 Tempo商業(yè)智能平臺(tái)
Tempo商業(yè)智能平臺(tái) Tempo人工智能平臺(tái)
Tempo人工智能平臺(tái) Tempo數(shù)據(jù)工廠平臺(tái)
Tempo數(shù)據(jù)工廠平臺(tái) Tempo指標(biāo)平臺(tái)
Tempo指標(biāo)平臺(tái) Tempo數(shù)據(jù)治理平臺(tái)
Tempo數(shù)據(jù)治理平臺(tái) Tempo主數(shù)據(jù)管理平臺(tái)
Tempo主數(shù)據(jù)管理平臺(tái)


 陜公網(wǎng)安備 61019002000171號(hào)
陜公網(wǎng)安備 61019002000171號(hào)



